How to Run Nuclei
Nuclei templates offer two primary execution methods:Supported Input Formats
For automation in pipelines, see Running Nuclei in CI/CD. Nuclei supports various input formats to run template against, including urls, hosts, ips, cidrs, asn, openapi, swagger, proxify, burpsuite exported data and more. To learn more on using input specify options, you can refer nuclei input formats. These inputs can be given to nuclei using-l and -input-mode flags.
-im flag to specify the input mode.
Executing Nuclei Templates
-t/templates
Default Templates
Most community templates from our nuclei-template repository are executed by default, directly from the standard installation path. The typical command is as follows:
- Certain tags and templates listed in the default
.nuclei-ignorefile are not included. - Code Templates require the
-codeflag to execute. - Headless Templates will not run unless you pass the
-headlessflag. - Fuzzing Templates will not run unless you pass the
-fuzzflag.
Executing Template Workflows
-w/workflows
Workflows can be executed using the following command:
Types of Templates
Template Filters
Nuclei engine supports three basic filters to customize template execution.-
Tags (
-tags) Filter based on tags field available in the template. -
Severity (
-severity) Filter based on severity field available in the template. -
Author (
-author) Filter based on author field available in the template.
~/nuclei-templates/ directory and has cve tags in it.
~/nuclei-templates/exposures/ directory and has config tag in it.
cve tags
AND has critical OR high severity AND geeknik as author of template.
Advanced Filters
Multiple filters can also be combined using the template condition flag (-tc) that allows complex expressions like the following ones:
idstringnamestringdescriptionstringtagsslice of stringsauthorsslice of stringsseveritystringprotocolstringhttp_methodslice of stringsbodystring (containing all request bodies if any)matcher_typeslice of stringextractor_typeslice of stringdescriptionstring
|| and &&) and used with DSL helper functions.
Similarly, all filters are supported in workflows as well.
WorkflowsIn Workflows, Nuclei filters are applied on templates or sub-templates running via workflows, not on the workflows itself.
Public Templates
Nuclei has built-in support for automatic template download/update from nuclei templates project which provides community-contributed list of ready-to-use templates that is constantly updated. Nuclei checks for new community template releases upon each execution and automatically downloads the latest version when available. optionally, this feature can be disabled using the-duc cli flag or the configuration file.
Custom Templates
Users can create custom templates on a personal public / private GitHub / AWS Bucket that they wish to run / update while using nuclei from any environment without manually downloading the GitHub repository everywhere. To use this feature, users need to set the following environment variables:For GitHub Project
For GitHub Project
For GitLab Project
For GitLab Project
For AWS Bucket
For AWS Bucket
For Azure Blob Storage
For Azure Blob Storage
$HOME/nuclei-templates/github/).
The directory structure of the custom templates looks as follows:
-t flag as follows:
-update flag.
AI-Powered Template Generation
-ai
Nuclei supports generating and running templates on-the-fly using AI capabilities powered by the ProjectDiscovery API. This feature allows you to perform quick, targeted scans without needing pre-written templates by describing what you want to detect in natural language.
Prerequisites:
- A ProjectDiscovery API key (Get one at cloud.projectdiscovery.io)
-
Configure your API key using one of these methods:
Method 1: Using CLI (Recommended)
Method 2: Environment Variable
- Finding Sensitive Information Leaks:
- Detecting Debug Information:
- Discovering Admin Interfaces:
- Identifying Exposed Secrets:
- Extract Page Titles
The
-ai flag requires an active internet connection to communicate with the ProjectDiscovery API. Generated templates are stored both locally on your computer and in your ProjectDiscovery cloud account for future reference. For privacy, your prompts and generated templates are not used for AI training.Currently, each user is limited to 100 AI template generation queries per day. This limit is subject to change based on usage patterns and to prevent abuse.Nuclei Flags
Rate Limits
Nuclei have multiple rate limit controls for multiple factors, including a number of templates to execute in parallel, a number of hosts to be scanned in parallel for each template, and the global number of request / per second you wanted to make/limit using nuclei, here is an example of each flag with description.
Feel free to play with these flags to tune your nuclei scan speed and accuracy. For more details on tuning these flag, you can refer mass-scanning-cli
Traffic Tagging
Many BugBounty platform/programs requires you to identify the HTTP traffic you make, this can be achieved by setting custom header using config file at$HOME/.config/nuclei/config.yaml or CLI flag -H / header
Setting custom header using config file
Setting custom header using CLI flag
Template Exclusion
Nuclei supports a variety of methods for excluding / blocking templates from execution. By default, nuclei excludes the tags/templates listed below from execution to avoid unexpected fuzz based scans and some that are not supposed to run for mass scan, and these can be easily overwritten with nuclei configuration file / flags. Nuclei engine supports two ways to manually exclude templates from scan,-
Exclude Templates (
-exclude-templates/exclude) exclude-templates flag is used to exclude single or multiple templates and directory, multiple-exclude-templatesflag can be used to provide multiple values. -
Exclude Tags (
-exclude-tags/etags) exclude-tags flag is used to exclude templates based in defined tags, single or multiple can be used to exclude templates.
Example of excluding single template
Example of multiple template exclusion
Example of excluding templates with single tag
Example of excluding templates with multiple tags
- .nuclei-ignore list - default list of tags and templates excluded from nuclei scan as default.
-include-templates or -include-tags flags. This will ensure that the specified templates or tags take precedence over any .nuclei-ignore or denylist entries.
Example of running blocked templates
Example of executing a specific template that is in the denylistSay that you have custom templates globbed (But you just want to execute a specific template.
*) in the denylist on the Nuclei configuration file.List Template Path
-tl option in Nuclei is used to list the paths of templates, rather than executing them. This can help you inspect which templates would be used for scan given your current template filter.
Scan on internet database
Nuclei supports integration with uncover module that supports services like Shodan, Censys, Hunter, Zoomeye, many more to execute Nuclei on these databases. Here are uncover options to use -Nuclei Config
Since release of v2.3.2 nuclei uses goflags for clean CLI experience and long/short formatted flags.
goflags comes with auto-generated config file support that coverts all available CLI flags into config file, basically you can define all CLI flags into config file to avoid repetitive CLI flags that loads as default for every scan of nuclei.
Default path of nuclei config file is $HOME/.config/nuclei/config.yaml, uncomment and configure the flags you wish to run as default.
Here is an example config file:
-config flags.
Running nuclei with custom config file
Nuclei Result Dashboard
Nuclei now allows seamless integration with the ProjectDiscovery Cloud Platform to simplify the visualization of Nuclei results and generate swift reports. This highly requested feature from the community enables easier handling of scan results with minimal effort. Follow the steps below to set up your PDCP Result Dashboard:- Visit https://cloud.projectdiscovery.io to create free PDCP API key.
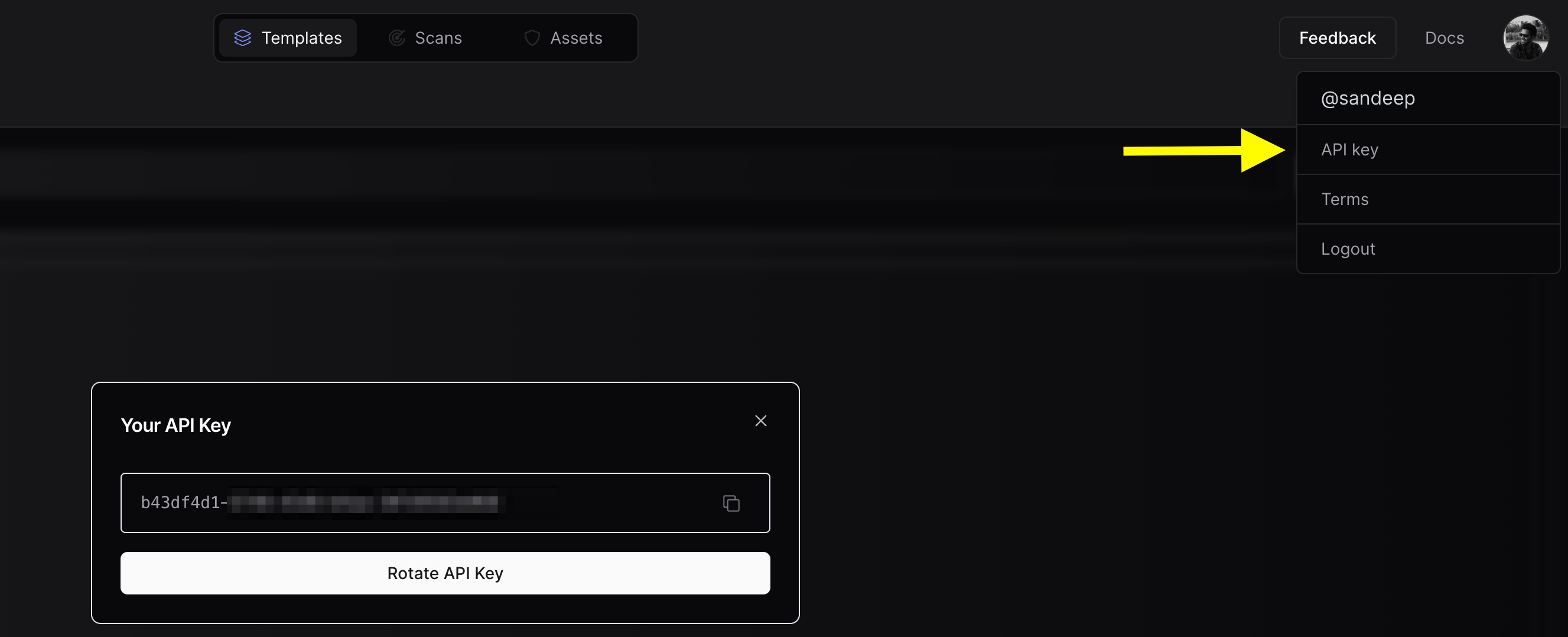
- Use the
nuclei -authcommand, enter your API key when prompted. - To perform a scan and upload the results straight to the cloud, use the
-cloud-uploadoption while running a nuclei scan.
Advanced Integration Options
Setting API key via environment variable Avoid entering your API key via interactive prompt by setting it via environment variable.ENABLE_CLOUD_UPLOAD environment variable.
DISABLE_CLOUD_UPLOAD_WRN environment variable.
$HOME/.pdcp/credentials.yaml
Nuclei Reporting
Nuclei comes with reporting module support with the release of v2.3.0 supporting GitHub, GitLab, and Jira integration, this allows nuclei engine to create automatic tickets on the supported platform based on found results.-rc, -report-config flag can be used to provide a config file to read configuration details of the platform to integrate. Here is an example config file for all supported platforms.
For example, to create tickets on GitHub, create a config file with the following content and replace the appropriate values:
$CVSSMetrics, $CVEID, $CWEID, $Host, $Severity, $CVSSScore, $Name
In addition, Jira is strict when it comes to custom field entry. If the field is a dropdown, Jira accepts only the case sensitive specific string and the API call is slightly different. To support this, there are three types of customfields.
nameis the dropdown valueidis the ID value of the dropdownfreeformis if the customfield the entry of any value
CLOSED_STATUS can be changed in the Jira template file using the status-not variable.
summary ~ TEMPLATE_NAME AND summary ~ HOSTNAME AND status != CLOSED_STATUS
deny-list can be used to exclude issues with a specific severity.
If you are running periodic scans on the same assets, you might want to consider -rdb, -report-db flag that creates a local copy of the valid findings in the given directory utilized by reporting module to compare and create tickets for unique issues only.
-me, -markdown-export flag, this flag takes directory as input to store markdown formatted reports.
Including request/response in the markdown report is optional, and included when -irr, -include-rr flag is used along with -me.
-se, -sarif-export flag. This flag takes a file as input to store SARIF formatted report.
- By uploading a SARIF file to SARIF Viewer
- By uploading a SARIF file to Github Actions
These are not official viewers of Nuclei and
Nuclei has no liability
towards any of these options to visualize Nuclei results. These are just
some publicly available options to visualize SARIF files.Scan Metrics
Nuclei expose running scan metrics on a local port9092 when -metrics flag is used and can be accessed at localhost:9092/metrics, default port to expose scan information is configurable using -metrics-port flag.
Here is an example to query metrics while running nuclei as following nuclei -t cves/ -l urls.txt -metrics
Passive Scan
Nuclei engine supports passive mode scanning for HTTP based template utilizing file support, with this support we can run HTTP based templates against locally stored HTTP response data collected from any other tool.Passive mode support is limited for templates having
{{BasedURL}} or {{BasedURL/}} as base path.Running With Docker
If Nuclei was installed within a Docker container based on the installation instructions, the executable does not have the context of the host machine. This means that the executable will not be able to access local files such as those used for input lists or templates. To resolve this, the container should be run with volumes mapped to the local filesystem to allow access to these files.Basic Usage
This example runs a Nuclei container againstgoogle.com, prints the results to JSON and removes the container once it
has completed:
Using Volumes
This example runs a Nuclei container against a list of URLs, writes the results to a.jsonl file and removes the
container once it has completed.